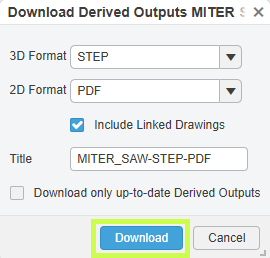
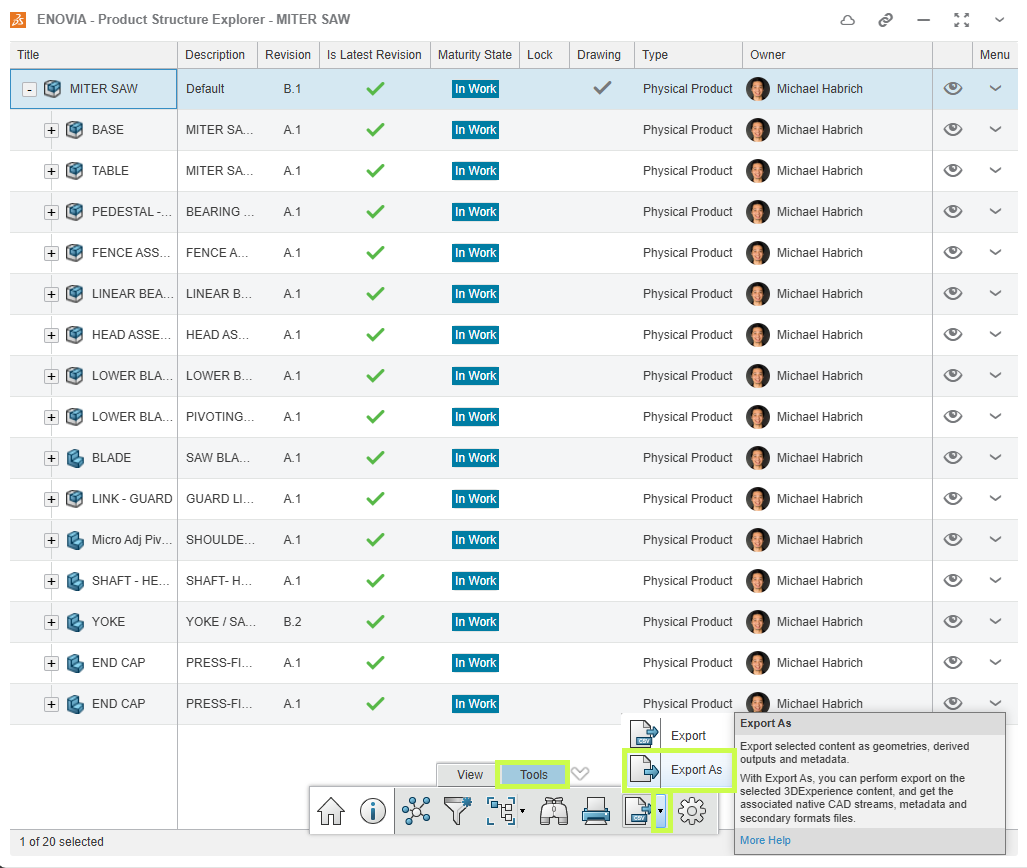
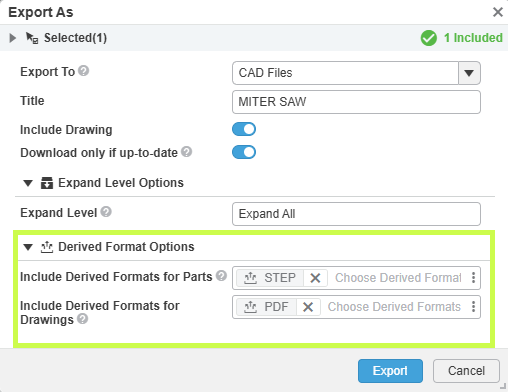
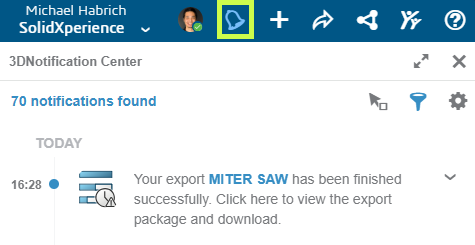
Présentation des concurrents
SOLIDWORKS est la plateforme de CAO de bureau de Dassault Systèmes, conçue dès le départ pour la conception de produits mécaniques. Elle couvre toutes les étapes du processus, de l’esquisse conceptuelle à la modélisation détaillée de pièces et d’assemblages. Elle prend également en charge la simulation, le rendu et la création de mises en plan prêtes pour la production. Son écosystème, qui comprend notamment PDM, Simulation, CAM et Visualize, est étroitement intégré. Sa communauté d’utilisateurs est également l’une des plus importantes dans le domaine de l’ingénierie. SOLIDWORKS excelle dans la conception de produits de consommation, les surfaces complexes, les constructions soudées et la tôlerie. Il convient également aux projets pour lesquels l’intention de conception doit être clairement communiquée entre les équipes.
Autodesk Inventor est un outil professionnel de conception mécanique 3D basé sur la modélisation paramétrique, la simulation et la conception d’outillage. Il s’intègre à l’écosystème élargi d’Autodesk, qui comprend notamment AutoCAD, Vault et Fusion 360. Traditionnellement, Inventor se distingue dans la conception d’équipements industriels comportant de grands assemblages et des structures mécanosoudées. Il est également bien adapté aux flux de fabrication qui reposent fortement sur une documentation 2D issue d’AutoCAD. Si votre entreprise travaille avec AutoCAD depuis longtemps, Inventor peut sembler être une transition naturelle vers la 3D.
Les points forts de chaque solution en un coup d’œil
Lorsqu’il est question de grandes structures et de constructions soudées, les deux plateformes sont compétentes et permettent d’obtenir de bons résultats. Cependant, leurs similitudes s’arrêtent rapidement là. Le principal avantage d’Inventor réside dans son interopérabilité approfondie avec AutoCAD.
SOLIDWORKS, de son côté, prend l’avantage dans presque toutes les autres catégories importantes pour les concepteurs mécaniques. Il offre des outils nettement plus performants pour la conception de produits de consommation et la création de surfaces complexes. Dans ces deux domaines, les capacités d’Inventor semblent plus limitées. Les flux de travail de tôlerie sont également plus matures et mieux adaptés à la production dans SOLIDWORKS. De plus, ses outils de simulation de bureau permettent d’effectuer des analyses plus poussées sans quitter l’environnement de modélisation.
Enfin, la communauté SOLIDWORKS et sa bibliothèque de ressources de formation sont beaucoup plus vastes que celles d’Inventor. Il s’agit d’un avantage considérable lorsqu’il faut résoudre un problème lié à un flux de travail peu familier ou exploiter le logiciel au-delà de ses usages habituels.
Conception mécanique : forces et faiblesses
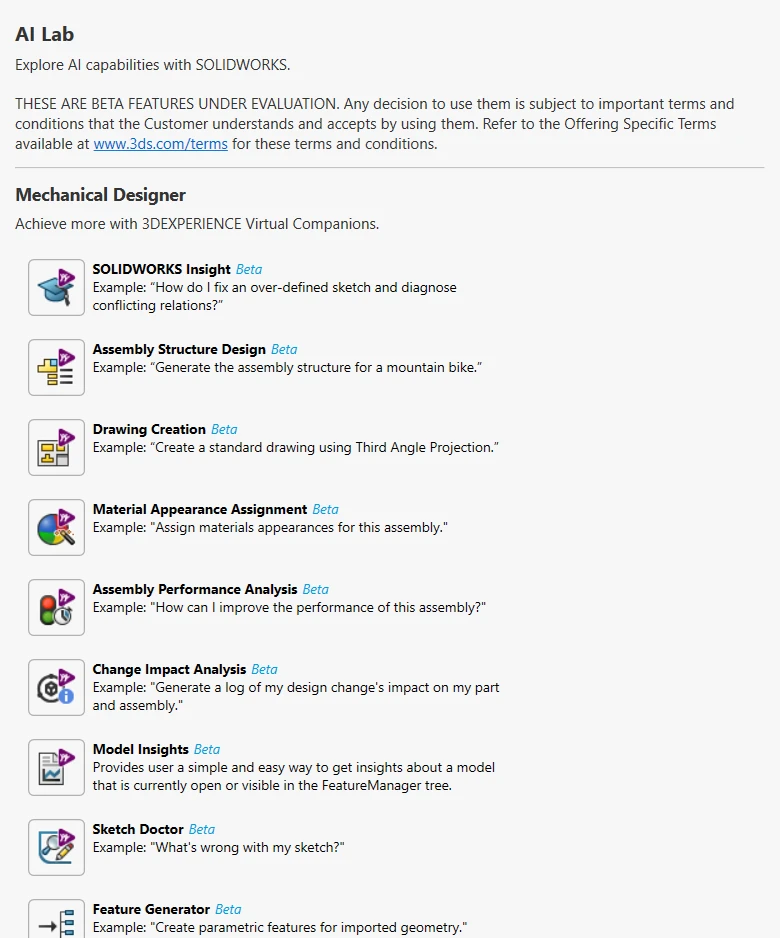
Pourquoi choisir SOLIDWORKS?
Forces
- Flux de travail intuitif basé sur les esquisses et les fonctions : SOLIDWORKS a été conçu dès le départ selon un paradigme basé sur la création d’une esquisse suivie d’une fonction, une approche particulièrement intuitive pour les pièces mécaniques. L’arbre FeatureManager est logique, les relations d’esquisse sont visuelles et prévisibles, et le logiciel permet généralement de revenir facilement modifier une fonction créée au début de la conception. L’intention de conception demeure intacte et les modifications peuvent être apportées facilement. La mise à jour automatique des pièces, mais également des assemblages, démontre toute la puissance de la conception paramétrique.
- Intégration de la simulation avec SOLIDWORKS Simulation : La possibilité d’effectuer des analyses par éléments finis, thermiques, de fatigue ou d’écoulement sans quitter l’environnement de modélisation représente un gain de temps considérable. Il n’est pas nécessaire d’exporter le modèle, de recréer le maillage et de réappliquer les charges dans un logiciel distinct. Il suffit de cliquer avec le bouton droit sur l’assemblage, de configurer une étude et d’itérer. Pour les concepteurs mécaniques qui doivent valider leurs concepts avant la création d’un prototype, cette boucle de conception et de validation étroitement intégrée est extrêmement précieuse.
- Tôlerie et constructions soudées : Les outils de tôlerie de SOLIDWORKS permettent de gérer des plis complexes, des outils de formage, des plis lissés et l’exportation de développés avec un niveau de maturité qu’Inventor tente encore d’atteindre. Les profils de construction soudée, les listes de pièces soudées et les fonctions d’ajustement et de prolongement sont efficaces et prêts pour la production. Si votre atelier coupe, plie et soude de l’acier quotidiennement, SOLIDWORKS s’adapte naturellement à votre réalité.
Faiblesses
- Performance avec les grands assemblages : SOLIDWORKS peut éprouver des difficultés avec les très grands assemblages de plus de 10 000 composants si les utilisateurs n’adoptent pas une approche rigoureuse. Il est notamment important d’utiliser le mode Allégé, les configurations SpeedPak et le mode Vérification des grandes conceptions. Historiquement, Inventor gérait les très grands assemblages avec un peu moins de contraintes dès l’installation, bien que l’écart entre les deux solutions se soit réduit.
- Coût et complexité de la gestion des données : SOLIDWORKS PDM Professional est une solution puissante, mais elle entraîne des coûts de licence importants ainsi qu’une charge supplémentaire pour les équipes informatiques. Elle nécessite notamment SQL Server, un serveur de coffre-fort dédié et le déploiement des clients. Pour les petites entreprises, le passage d’une gestion désorganisée fondée sur des dossiers à un environnement PDM correctement structuré peut être exigeant. Cette transition représente un défi tant sur le plan financier qu’administratif.
- Pression liée à la tarification par abonnement : La transition de Dassault Systèmes vers les abonnements et la plateforme 3DEXPERIENCE a créé une certaine incertitude. Celle-ci touche particulièrement les utilisateurs de longue date possédant des licences perpétuelles. Les coûts ont tendance à augmenter, et certaines fonctionnalités évoluent vers des flux de travail connectés au cloud. Or, les ateliers de conception mécanique ne sont pas tous prêts à s’y adapter.
Pourquoi choisir Autodesk Inventor?
Forces
- Frame Generator et assemblages boulonnés : Le Frame Generator d’Inventor est véritablement excellent. Il suffit de sélectionner un profilé structurel dans une bibliothèque et de dessiner un squelette. L’outil génère ensuite la structure avec des coupes d’onglet automatiques, des traitements d’extrémité et une nomenclature prête pour la fabrication. Pour les personnes qui conçoivent des convoyeurs, des protecteurs de machines ou des structures en acier, ce flux de travail est rapide et fiable.
- Intégration avec AutoCAD et Vault : Si votre entreprise possède des décennies de données héritées d’AutoCAD, Inventor peut lire et référencer nativement les fichiers DWG. Vault, l’outil de gestion de données d’Autodesk, relie les modèles Inventor aux dessins AutoCAD sans les problèmes liés à la conversion des formats. Cette continuité est importante lorsqu’il faut entretenir des équipements initialement dessinés avec AutoCAD R14.
- Conception basée sur des règles avec iLogic : iLogic permet d’intégrer des règles de conception directement dans les pièces et les assemblages sans avoir à utiliser une API complète. Pour les produits configurables, comme les convoyeurs de longueurs personnalisées, les supports de différentes dimensions ou les variantes de boîtiers, iLogic peut contrôler les cotes, supprimer des fonctions et remplacer des composants à l’aide de simples règles conditionnelles. Cette approche rend l’automatisation plus accessible que la création de macros complètes.
Faiblesses
- Outils de surfacique limités : Les outils de surfacique d’Inventor peuvent rapidement montrer leurs limites lorsqu’une conception mécanique comprend des formes organiques ou des raccordements complexes. C’est également le cas lorsque le produit exige une esthétique plus soignée. La création de surfaces complexes à courbure continue peut alors devenir difficile. SOLIDWORKS, en revanche, gère ce type de géométrie avec davantage de facilité.
- Environnement de mise en plan vieillissant : Malgré les améliorations apportées au fil des années, l’environnement de mise en plan d’Inventor conserve certaines particularités. Celles-ci sont héritées de la logique d’AutoCAD. La gestion des bulles, la personnalisation des nomenclatures et l’annotation des vues peuvent sembler moins intuitives que dans SOLIDWORKS. Cette différence est particulièrement marquée pour les assemblages comportant des centaines de composants.
- Écosystème et communauté plus restreints : Il peut être plus long de trouver rapidement une réponse à un problème précis dans Inventor. Les forums sont actifs, mais plus petits. Le nombre de modules complémentaires offerts par des tiers est également plus limité, tout comme le contenu de formation, particulièrement pour les sujets avancés. Lorsqu’un problème survient un vendredi à 16 h alors qu’une échéance approche, la taille de la communauté devient un véritable avantage.
Pourquoi SOLIDWORKS l’emporte pour la conception mécanique
Après avoir travaillé pendant plusieurs années avec les deux plateformes, je suis passé à SOLIDWORKS il y a une dizaine d’années et je ne suis jamais revenu en arrière. La raison est simple : SOLIDWORKS raisonne comme un concepteur mécanique.
Chaque outil, menu et flux de travail semble avoir été créé par une personne ayant déjà dû communiquer une conception à un machiniste ou à un fabricant à partir d’une planche à dessin.
Inventor est un logiciel compétent, véritablement compétent. Cependant, il donne parfois l’impression d’être une couche 3D ajoutée à une philosophie héritée d’AutoCAD. Cette approche semble progressivement perdre du terrain alors qu’Autodesk concentre davantage ses efforts sur Fusion 360.
Inventor propose également plusieurs fonctionnalités qui ne s’adressent pas nécessairement aux concepteurs mécaniques. Par exemple, 3ds Max est principalement destiné aux studios d’animation. Les outils de conception d’usines s’adressent davantage aux ingénieurs en fabrication, tandis que les fonctionnalités BIM sont conçues pour un groupe d’utilisateurs très spécialisé.
SOLIDWORKS a été conçu nativement pour la 3D, et cet ADN est perceptible dans toutes les interactions. Il propose des outils réellement utiles aux concepteurs, notamment Toolbox, Design Checker, TolAnalyst, la détection des interférences, la détection des collisions, la mise à plat des surfaces ainsi que le routage de tuyaux, de tubes et de systèmes électriques.
Au-delà de cette expérience générale, deux fonctionnalités distinguent particulièrement SOLIDWORKS.
Fonctionnalité 1 : préserver l’intention de conception grâce aux configurations
Le système de configurations de SOLIDWORKS est extrêmement puissant pour la conception mécanique. Un seul fichier de pièce peut représenter toute une famille de composants comportant différentes longueurs, dimensions d’alésage ou épaisseurs de matériau. Ces variations peuvent être contrôlées à l’aide d’une famille de pièces ou de paramètres de configuration manuels.
Il ne s’agit pas uniquement d’une fonctionnalité pratique. Cette approche reflète la réalité des produits mécaniques. Un support peut être offert en cinq dimensions. Un arbre peut comporter trois options de rainures de clavette. Les configurations permettent de modéliser cette réalité une seule fois et de la gérer dans un seul fichier.
L’approche iPart et iAssembly d’Inventor repose sur un principe semblable, mais son exécution est plus complexe. C’est particulièrement le cas lorsque les configurations interagissent avec les mises en plan, les nomenclatures et le système PDM.
Fonctionnalité 2 : l’associativité entre les mises en plan et les modèles
Les mises en plan SOLIDWORKS ne sont pas de simples vues d’un modèle. Elles constituent des fenêtres dynamiques et bidirectionnelles vers celui-ci. Il est possible de coter une fonction directement dans la mise en plan et d’utiliser cette cote pour modifier le modèle.
Les annotations et les tolérances suivent également le modèle sous forme de données MBD. Il en va de même pour les informations de cotation et de tolérancement géométriques, intégrées à la définition basée sur le modèle.
Pour un concepteur mécanique, le livrable final peut être une mise en plan de fabrication ou un modèle 3D annoté envoyé à un atelier d’usinage CNC. Cette associativité permet de réduire les erreurs, d’accélérer les demandes de modification technique et de limiter le temps consacré à comparer le modèle et la mise en plan.
Conclusion
Les deux outils permettent de concevoir des pièces et de produire des mises en plan. Toutefois, SOLIDWORKS offre une expérience plus intégrée et plus intuitive pour la conception de produits mécaniques. Il convient particulièrement aux flux de travail qui réunissent les pièces, les assemblages, les mises en plan, la simulation et la communication avec les équipes de fabrication.
Le nombre réduit d’environnements d’interface simplifie l’expérience utilisateur. Les fonctions de tôlerie et de construction soudée peuvent notamment être utilisées directement dans l’environnement de pièce. Inventor, en comparaison, comprend environ six environnements distincts conçus pour des utilisations précises.
SOLIDWORKS continue d’évoluer en fonction de la manière dont les concepteurs mécaniques travaillent réellement. Cette approche contribue à en faire l’un des logiciels de CAO les plus utilisés dans une grande variété de marchés et de disciplines.
Prêt à découvrir si SOLIDWORKS convient à votre flux de conception mécanique? Communiquez avec l’équipe de Solidxperts pour discuter de vos besoins et explorer la solution la mieux adaptée à votre entreprise.


Vous avez des questions ? Besoin d’aide ? Demandez à l’un de nos experts.
Que vous soyez prêt à commencer ou que vous ayez quelques questions supplémentaires, vous pouvez nous contacter sans frais :










 Onshape AI Advisor
Onshape AI Advisor